
Using A.I at Tetrix
Effectiveness
At Tetrix, when implementing AI features, our focus is on ensuring that AI adds real value. We view AI as just one tool among many in our technology toolkit. We don’t begin with a technology; instead, we start with an idea for a feature and select the appropriate technology to bring it to life. It’s essential for us that every feature we develop at Tetrix serves a clear purpose and meets our users’ needs.
Security
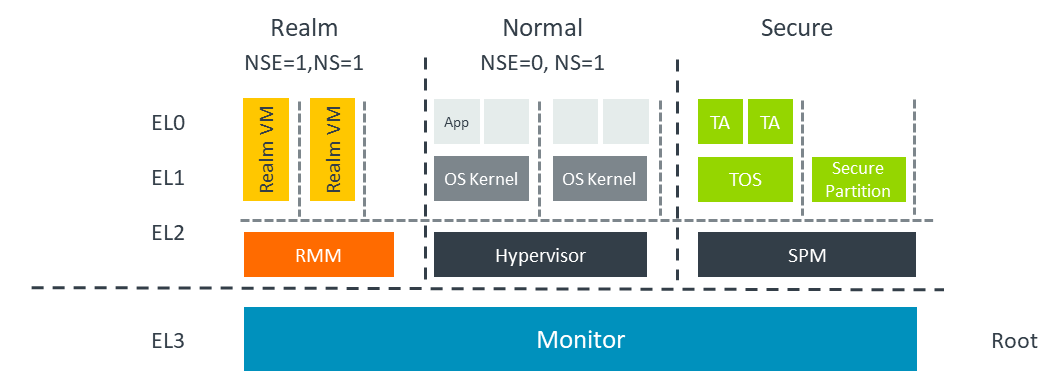
Security is at the core of our AI integration process. Currently, Tetrix outsources AI tasks to Google Gemini, a decision we acknowledge comes with security implications. We are actively working toward self-hosting our models, though this presents a significant challenge. Recently, Apple outlined its AI and privacy standards, emphasizing that most AI tasks should be processed on in-house servers using the Arm CCA Hardware Architecture. While Tetrix does not have the capability to develop such hardware, we plan to implement a similar approach by ensuring end-to-end encryption for our operations. For more details on Private Cloud Compute, you can read Apple’s blog post: https://security.apple.com/blog/private-cloud-compute/
Speed
Currently, using Google Gemini ensures consistent processing speeds. However, as we transition to hosting our own models, speed will become a key consideration. Machine learning models require significant computing power, so it’s crucial for us to run them efficiently. Because of this, our shift to locally hosted models is part of a long-term strategy.
Roadmap to local hosting
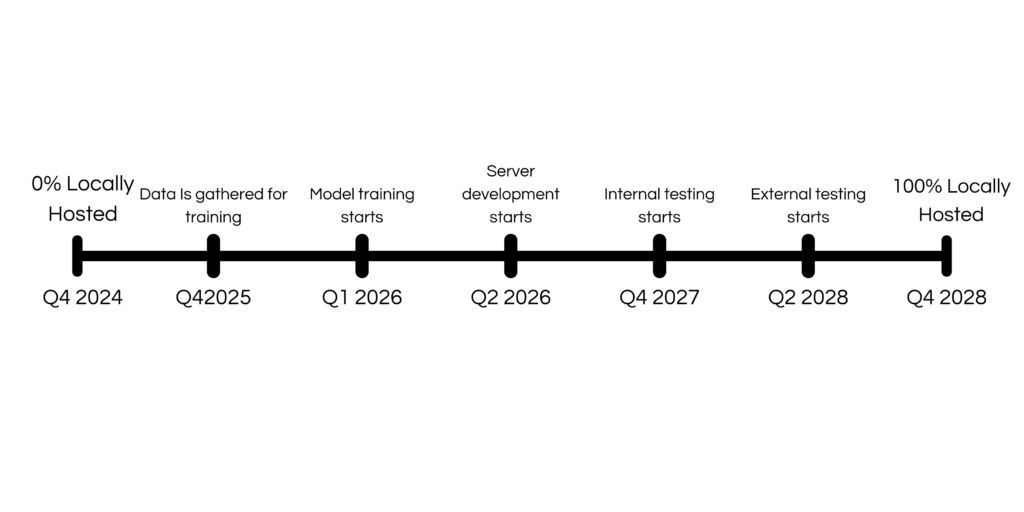
When designing our roadmap for local hosting, we aimed to be realistic about both the cost and complexity of this undertaking. At Tetrix, we are fully committed to fulfilling our self-hosting and security promises, and we are prepared to face the challenges ahead to achieve this goal.
Noah Moller
Author